

Note: "Then & Now" (T&N) is a new version of what used to be the "Oldies but Goodies" (OBG) series. To demonstrate the superiority of a sound theoretical foundation relative to the industry's fad-driven "cookbook" practices, as well as the evolution/progress of RDM, I am re-visiting my 2000-06 debunkings, bringing them up to my with my knowledge and understanding of today. This will enable you to judge how well my arguments have held up and appreciate the increasing gap between scientific progress and the industry’s stagnation, if not outright regress.
This is a re-published series of several DBDebunk 2001 exchanges about Simon Wlliams' so-called "Associative Model of Data" (AMD), academic claims of its superiority over RDM ("The Associative Data Model Versus the Relational model") and predictions of the demise of the latter ("The decline and eventual demise of the Relational Model of Data").
Part 1 was an email exchange among myself (FP), Chris Date (CJD) and Lee Fesperman (LF) in reaction to Williams' claims that started the series.
Part 2 was my response to a reader's email questioning our dismissal of Williams's claims.
Part 3 was my email exchange with Williams, where he provided his definition of a data model on which I conditioned any discussion with him and where I debunked it.
Part 4 is my response to a reader's comments on Parts 1-3.
Note: In "Setting Matters Straight" posts I debunk online pronouncements that involve fundamentals which I first post on LinkedIn. The purpose is to induce practitioners to test their foundation knowledge against our debunking, where we explain what is correct and what is fallacious. For in-depth treatments check out the POSTS and our PAPERS, LINKS and BOOKS (or organize one of our on-site/online SEMINARS, which can be customized to specific needs). Questions and comments are welcome here and on LinkedIn.
In Part 3 we set the matter straight about normalization to 1NF. In this part we do it wit respect to further normalization to 5NF. Non-1NF relations (i.e., with relation-valued attributes) are no longer part of industry practice, so we focus on 2NF-5NF violations. The term further normalization originates with Codd, who initially thought 1NF was sufficient and 2NF-5NF were discovered later (hence, further = beyond 1NF). The industry lumps both under normalization, but the two are distinct (e.g., only further normalization involves redundancy).
What's right/wrong with the following?
“So, what is this theory of normal forms? It deals with the mathematical construct of relations (which are a little bit different from relational database tables). First, second, and third normal forms are the basic normal forms in database normalization. Normalization in relational databases is a design process that minimizes data redundancy and avoids update anomalies. Basically, you want each piece of information to be stored exactly once; if the information changes, you only have to update it in one place. The normalization process consists of modifying the design through different stages, going from an unnormalized set of relations (tables), to the first normal form, then to the second normal form, and then to the third normal form.”--Vertabelo.com
Note: "Then & Now" (T&N) is a new version of what used to be the "Oldies but Goodies" (OBG) series. To demonstrate the superiority of a sound theoretical foundation relative to the industry's fad-driven "cookbook" practices, as well as the evolution/progress of RDM, I am re-visiting my 2000-06 debunkings, bringing them up to my with my knowledge and understanding of today. This will enable you to judge how well my arguments have held up and appreciate the increasing gap between scientific progress and the industry’s stagnation, if not outright regress.
This is a re-published series of several DBDebunk 2001 exchanges on Simon Wlliams' so-called "Associative Model of Data" (AMD), academic claims of its superiority over RDM ("The Associative Data Model Versus the Relational model") and predictions of the demise of the latter ("The decline and eventual demise of the Relational Model of Data").
Part 1 was an email exchange among myself (FP), Chris Date (CJD) and Lee Fesperman (LF) in reaction to Williams' claims that started the series. Part 2 was my response to a reader's email questioning our dismissal of Williams's claims. Part 3 was my email exchange with Williams where he provided his definition of a data model on which I conditioned any discussion with him and I debunked it. Part 4 is my response to a reader's comments on my previous posts in the series.
09/19/23: For the latest on 1NF see: FIRST NORMAL FORM - A DEFINITIVE GUIDE
Note: In "Setting Matters Straight" posts I debunk online pronouncements that involve fundamentals which I first post on LinkedIn. The purpose is to induce practitioners to test their foundation knowledge against our debunking, where we explain what is correct and what is fallacious. For in-depth treatments check out the POSTS and our PAPERS, LINKS and BOOKS (or organize one of our on-site/online SEMINARS, which can be customized to specific needs). Questions and comments are welcome here and on LinkedIn.
(Continued from Part 2)
In this part we set matters straight about first normal form (1NF)
What's right/wrong about this database picture?
“A relation is in first normal form (1NF) if (and only if):In practice, 1NF means that you should not have lists or other composite structures as attribute values. Below is an example of a relation that does not satisfy 1NF criteria:This relation is not in 1NF because the courses attribute has multiple values.
- Each attribute contains only one value.
- All attribute values are atomic, which means they can’t be broken down into anything smaller.
STUDENT-COURSES
==================================================
STUDENT COURSES
-=======================--------------------------
Jane Smith Databases, Mathematics
John Lipinsky English Literature, Databases
Dave Beyer English Literature, Mathematics
--------------------------------------------------
To transform this relation to the first normal form, we should store each course subject as a single value, so that each student-course assignment is a separate tuple.”
--Vertabelo.com
Note: "Then & Now" (T&N) is a new version of what used to be the "Oldies but Goodies" (OBG) series. To demonstrate the superiority of a sound theoretical foundation relative to the industry's fad-driven "cookbook" practices, as well as the evolution/progress of RDM, I am re-visiting my 2000-06 debunkings, bringing them up to my with my knowledge and understanding of today. This will enable you to judge how well my arguments have held up and appreciate the increasing gap between scientific progress and the industry’s stagnation, if not outright regress.
This is a re-published series of several DBDebunk 2001 exchanges on Simon Wlliams' so-called "Associative Model of Data" (AMD), academic claims of its superiority over RDM ("The Associative Data Model Versus the Relational model") and predictions of the demise of the latter ("The decline and eventual demise of the Relational Model of Data").
Part 1 was the email exchange among myself (FP), Chris Date (CJD) and Lee Fesperman (LF) in reaction to Williams' claims that started the series. Part 2 was my response to a reader's email questioning our dismissal of Williams's claims. Part 3 is my email exchange with Williams: he provided his "definition" of a data model on which I conditioned any discussion with him and I proved my point by debunking it.
Note: In "Setting Matters Straight" posts I debunk online pronouncements that involve fundamentals which I first post on LinkedIn. The purpose is to induce practitioners to test their foundation knowledge against our debunking, where we explain what is correct and what is fallacious. For in-depth treatments check out the POSTS and our PAPERS, LINKS and BOOKS (or organize one of our on-site/online SEMINARS, which can be customized to specific needs). Questions and comments are welcome here and on LinkedIn.
(Continued from Part 1)
What's right/wrong about this database picture?
“So, what is this theory of normal forms? It deals with the mathematical construct of relations (which are a little bit different from relational database tables). The normalization process consists of modifying the design through different stages, going from an unnormalized set of relations (tables), to the first normal form, then to the second normal form, and then to the third normal form.”
--Vertabelo.com
Note: "Then & Now" (t&n) is a new version of what used to be the "Oldies but Goodies" (obg) series. To demonstrate the superiority of a sound theoretical foundation relative to the industry's fad-driven "cookbook" practices, as well as the evolution/progress of RDM, I am re-visiting my 2000-06 debunkings, bringing them up to my with my knowledge and understanding of today. This will enable you to judge how well my arguments have held up and appreciate the increasing gap between scientific progress and the industry’s stagnation, if not outright regress.
This is a re-published series of several DBDebunk 2001 exchanges on Simon Wlliams' so-called "Associative Model of Data" (AMD), academic claims of its superiority over RDM ("The Associative Data Model Versus the Relational model") and predictions of the demise of the latter ("The decline and eventual demise of the Relational Model of Data").
Part 1 was the email exchange among myself (FP), Chris Date (CJD) and Lee Fesperman (LF) in reaction to Simon Williams' claims that started the series. Part 2 is my response to a reader's email questioning our dismissal of Williams's claims. (The reader's comments are in quotes.)
Note: In "Setting Matters Straight" posts I debunk online pronouncements that involve fundamentals which I first post on LinkedIn. The purpose is to induce practitioners to test their foundation knowledge against our debunking, where we explain what is correct and what is fallacious. For in-depth treatments check out the POSTS and our PAPERS, LINKS and BOOKS (or organize one of our on-site/online SEMINARS, which can be customized to specific needs). Questions and comments are welcome here and on LinkedIn.
What's right/wrong with this database picture?
“Normalization in relational databases is a design process that minimizes data redundancy and avoids update anomalies. Basically, you want each piece of information to be stored exactly once; if the information changes, you only have to update it in one place. The theory of normal forms gives rigorous meaning to these informal concepts. There are many normal forms. In this article, we’ll review the most basic:
First normal form (1NF)
Second normal form (2NF)
Third normal form (3NF)
There are normal forms higher than 3NF, but in practice you usually normalize your database to the third normal form or to the Boyce-Codd normal form, which we won’t cover here.”
--Vertabelo.com
Note: "Then & Now" (T&N) is a new version of what used to be the "Oldies but Goodies" (OBG) series. To demonstrate the superiority of a sound theoretical foundation relative to the industry's fad-driven "cookbook" practices, as well as the evolution/progress of RDM, I am re-visiting my 2000-06 debunkings, bringing them up to my with my knowledge and understanding of today. This will enable you to judge how well my arguments have held up and appreciate the increasing gap between scientific progress and the industry’s stagnation, if not outright regress.
“Codd's aim was to free programmers from having to know the physical structure of data. Our aim is to free them in addition from having to know its logical structure.”
--Simon Williams, LazySoft
This series is a re-publication of several DBDebunk 2001 posts in response to Simon Wlliams' so-called "Associative Model of Data", academic claims of superiority over RDM ("The Associative Data Model Versus the Relational model") and predictions of the demise of the latter ("The decline and eventual demise of the Relational Model of Data").
Part 1 is the email exchange among myself (FP), Chris Date (CJD) and Lee Fesperman (LF) in reaction to Williams' claims that started the whole thing.
Q: “I have done data normalization on dummy data and would like to know if I did it correctly. If it is done correctly, I would also like to ask two things below, because it is about 3NF.
1NF: This table should be 1NF.

2NF: I selected composite key (userID and Doors) as they represent minimal candidate key and got three tables applying FD rule.

3NF: Applying the rule of transitive dependency on 1st table in 2NF, I got out 4 tables (showing only first two, because the last two remain unchanged).
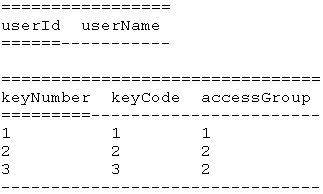
Questions: Is this database normalisation correct? If not could you point me where I did mistake? If answer on first question is True: Should the last table in 3NF be transformed into two tables, given it is not in correct Third normal form. Two non-key atributes have FD keycode -> accessGroup.”
Note: In "Setting Matters Straight" posts I debunk online pronouncements that involve fundamentals which I first post on LinkedIn. The purpose is to induce practitioners to test their foundation knowledge against our debunking, where we explain what is correct and what is fallacious. For in-depth treatments check out the POSTS and our PAPERS, LINKS and BOOKS (or organize one of our on-site/online SEMINARS, which can be customized to specific needs). Questions and comments are welcome here and on LinkedIn.
In a previous SMS post I debunked an attempt to express something important about database practice that was handicapped by lack of foundation knowledge. Here is another example.
“This Codd guy might have been onto something. Unfortunately, normalization is usually taught in a somewhat backwards, overly technical way. If you start with concepts, connections between them and details about them, you usually are already at a fairly high normal form without going through any formal normalization steps.”--LinkedIn.com
Note: "Then & Now" (T&N) is a new version of what used to be the "Oldies but Goodies" (OBG) series. To demonstrate the superiority of a sound theoretical foundation relative to the industry's fad-driven "cookbook" practices, as well as the evolution/progress of RDM, I am re-visiting my 2000-06 debunkings, bringing them up to my with my knowledge and understanding of today. This will enable you to judge how well my arguments have held up and appreciate the increasing gap between scientific progress and the industry’s stagnation, if not outright regress.
This was an email exchange with a reader, first published as ON ON-THE-FLY THINKING in March 2005.
“From a quick one-page marketing article:"Relational databases are one to two orders of magnitude too slow."The quote is directly from the company's owner who "...created two well-known relational database systems, Ingres and Postgres." Further from the reporter:
--Michael Stonebreaker, quoted in Data on the Fly, Forbes"Unlike traditional database programs, Streambase analyzes data without storing it to disk, performing queries on data as it flows."Hmmm... didn't know that the Relational Model of Data specifically proscribed in-memory implementations.”
Note: In "Setting Matters Straight" posts I debunk online Q&As that involve fundamentals which I first post on LinkedIn. The purpose is to induce practitioners to test their foundation knowledge against our debunking, where we explain what is correct and what is fallacious. For in-depth treatments check out the POSTS and our PAPERS, LINKS and BOOKS (or organize one of our on-site/online SEMINARS, which can be customized to specific needs). Questions and comments are welcome here and on LinkedIn.
“...The relational model organizes data through relations (aka tables). You then normalize it in one of six forms. By normalizing data you:--LinkedIn.com
- Reduce redundancy
- Ensure consistency
- Optimize for atomic inserts, updates and deletes
The biggest drawback ... are keys that let you join different tables across multiple systems.”
(First published in 2006)
Note: "Then & Now" (T&N) is a new version of the old "Oldies but Goodies" (OBG) series. To demonstrate the superiority of a sound theoretical foundation relative to the industry's fad-driven "cookbook" practices, as well as the evolution/progress of RDM, I am re-visiting my 2000-06 debunkings, bringing them up to my with my knowledge and understanding of today. This will enable you to judge how well my arguments have held up and appreciate the increasing gap between scientific progress and the industry’s stagnation, if not outright regress.
(Nothing to add on re-publication.)
There is massive ignorance in data management, but the vociferous kind (VI) is the purview of a special breed that is characterized by one or more of the following:
1. Lack of knowledge and understanding of, and appreciation for data fundamentals in general and relational concepts, principles and methods in particular.
2. Unwillingness to let it stand in the way of pronouncing extensively on the subject.
3. Inability and/or unwillingness to respond to evidence of ignorance and/or to reason.
4. Lack of interest — often admitted — in truth and correctness.
5. Focus on self promotion and appeasement of the industry by riding fads, or telling (uninformed) audiences what they want to hear.
The combination of 1 and 2 characterizes the Unskilled and Unaware of It, 2 is the vociferous part. Frankfurt defined 4 as bullshit. 5 is just self-aggrandizing.
“In a RDBMS, a table is columned rows, as in you treat individual rows as an actual entity while the columns are its attributes. In an excel tab, you can create a column, but it doesn't have to have all the same data types in that column, nor does one row have to represent one entity. It's more free form ... All in all, RDB is relational because it's column based rows and constrained to that format, while non relational can have free form like an excel. When you have rows that are uniform (constrained to what the column should be), you create entities as tables, and link them through columns to keep track of the relationships.”I posted this on LinkedIn as one of my "To Laugh or Cry?" items which, unlike "Setting Matters Right" posts, are beyond debunking. But the exchange that followed made me realize that there is, nevertheless, pedagogical value to it: it expresses something important, but poorly due to author's lack of foundation knowledge.--Quora.com
Note: "Then & Now" (T&N) is a new version of what used to be the "Oldies but Goodies" (OBG) series. To demonstrate the superiority of a sound theoretical foundation relative to the industry's fad-driven "cookbook" practices, as well as the evolution/progress of RDM, I am re-visiting my 2000-06 debunkings, bringing them up to my with my knowledge and understanding of today. This will enable you to judge how well my arguments have held up and appreciate the increasing gap between scientific progress and the industry’s stagnation, if not outright regress.
(first published 04/05/02)
"I had a question about the missing-values suggestion in PRACTICAL ISSUES IN DATABASE MANAGEMENT, page 234. You write:
"Table operations would have to be modified to yield results with as many tables as there are types of propositions with only known values."
How would this be represented in a language like Tutorial D, where relvars are required to be strongly typed? One possible idea is to make use of type inheritance. Suppose I had a domain of tuple values {x,a,b,c} (all integers, say) where x is not allowed to be missing but a, b, and c are allowed to be missing. Suppose we extended the domains of a, b, and c with an "imaginary" special value that we will never represent, which I will show for diagram purposes only as '?'. Then the domain can be split into parts:
XABC {x,a,b,c} possrep: {X: int, A: int, B: int, C: int}
XAB {x,a,b,'?'} possrep: {X: int, A: int, B: int}
XAC {x,a,'?',c} possrep: {X: int, A: int, C: int}
XBC {x,'?',b,c} possrep: {X: int, B: int, C: int}
XA {x,a,'?','?'} possrep: {X: int, A: int}
XB {x,'?',b,'?'} possrep: {X: int, B: int}
XC {x,'?','?',c} possrep: {X: int, C: int}
X {x,’?','?','?'} possrep: {X: int}
Using Mr. Date's specialization by constraint idea, we can inherit all the subtuple types from the main tuple type. Updates could make a tuple change type. A relation of relations of XABC type could be used to return results of a query. Each relation within the relation would contain one subtype.
However, the exponential explosion of possible subtypes would be very difficult to handle, practically speaking. As you admit in your book, a real DBMS might have to handle thousands of small subtables. This cannot be passed off as an "implementation detail" since table operations "yield results" at the user presentation level. No matter how efficient the underlying system might be, this seems unacceptable. Perhaps we have to fall back on default values after all."
Note: In "Setting Matters Straight" posts I debunk online Q&As that involve fundamentals which I first post on LinkedIn. The purpose is to induce practitioners to test their foundation knowledge against our debunking, where we explain what is correct and what is fallacious. For in-depth treatments check out the POSTS and our PAPERS, LINKS and BOOKS (or organize one of our on-site/online SEMINARS, which can be customized to specific needs). Questions and comments are welcome here and on LinkedIn.
Q: “What is a relation in database?”
A: “Relational databases were so named in 1970 by computer scientist E. F. Codd because the tables are themselves relations, which is a mathematical term. What makes a relation (aka a table) a relation? Basically:See? There’s nothing about relationships between tables in the definition of a relation. You could have a relational database that contains just one relation. If there’s any relationship described in a relation, it’s actually the relationship between the columns within a relation. That is, the value "Pittsburgh" goes with the value "Steelers" on a given row because the relation is defined as "pro football teams by city" and therefore there’s a linkage between some values in the set of football teams and the set of city names.” --Quora.com
- A relation has a heading, which names a finite set of columns.
- Columns are defined by their name and their type.
- A relation has a finite set of tuples (aka rows), and every tuple has the same set of columns (i.e. same name and type) as those named in the heading.
- Being finite sets, both the set of columns in the heading and the set of tuples in the relation have no duplicates and no inherent order.
09/19/23: For the latest on this subject see: FIRST NORMAL FORM - A DEFINITIVE GUIDE
“A commonly used example of a table that is not in 2-NF is one with repeated attributes (i.e. child1, child2, child3). However, after examining the definition of 2NF in your book PRACTICAL ISSUES IN DATABASE MANAGEMENT, it seems to me that tables such as these do in fact satisfy 2NF. Am I missing something?” --Reader
Note: In "Setting Matters Straight" I post on LinkedIn online Q&As that involve fundamentals under the header "What's Right and Wrong with this Database Picture" and then debunk them here. The purpose is to induce practitioners to test their foundation knowledge against our debunking, where we explain what is correct and what is fallacious. For in-depth treatments check out the POSTS and our PAPERS, LINKS and BOOKS (or organize one of our on-site/online SEMINARS, which can be customized to specific needs). Questions and comments are welcome here and on LinkedIn.
Q: “I'm not sure what this means: "The order of the rows and columns is immaterial to the DBMS?" -- could anyone explain?”
A: “It means two things:
The engine is under no obligation to insert new rows immediately following the previously inserted row(s)... During processing of selects, the optimizer is free to use any index it finds efficient to use or none at all... For this reason, if the order of returned data is important to your processing, then you must include an ORDER BY clause.”
Q: “How do you reorder fields in the database?”
A: “Depends on how you define "reorder". What view of your data are you trying to set the order. Are you in Table Design view? ... Are you looking at form? The answer is different depending on what you are referring to.”--Quora.com
Note: To demonstrate the correctness and stability due to a sound theoretical foundation relative to the industry's fad-driven "cookbook" practices, I am re-publishing as "Oldies But Goodies" material from the old DBDebunk.com (2000-06), Judge for yourself how well my arguments hold up and whether the industry has progressed beyond the misconceptions those arguments were intended to dispel. I may revise, break into parts, and/or add comments and/or references. You can acquire foundation knowledge by checking out our POSTS, BOOKS, PAPERS, LINKS (or, even better, organize one of our on-site SEMINARS, which can be customized to specific needs).
The following is an email exchange with a reader and DBMS designer.
(originally published in 2001)
Reader:
"I would like to hear your (or Date's) opinion on The Suneido Database … it seems to me self-contradictory. They aren't typed ... so how can they define operators, or even the idea of domains. They also say they include administrative commands, which as far as I understand isn't allowed in the THIRD MANIFESTO. While they do not claim to be an implementation of the Manifesto, their claims that their database language was created by CJ Date do not sound appropriate."
"They don't know what [domains (distinct from programming data types)] are and what their function in the RDM is. That's common for all DBMS vendors, the claims of which should be always taken with more than a grain of salt."
Note: "Setting Matters Straight" is a new format: I post on LinkedIn an online Q&A involving data fundamentals that I subsequently debunk in a post here. This is to encourage readers to test their foundation knowledge against our debunking here, where we confirm what is correct and correct what is fallacious. For in-depth treatments check out the POSTS and our PAPERS, LINKS and BOOKS (or organize one of our on-site/online SEMINARS, which can be customized to specific needs). Questions and comments are welcome here and on LinkedIn.
Q: “How do I avoid too many relations in databases?”
A: “You don’t. Every relation is there to store meaningful data, hopefully you do not define database relations for data that are not to be stored in your database.”
A: “By following proper design principles. Normalization, standard data patterns, and progressing from logical to physical always. Never denormalize (or avoid normalizing in the first place) because performance never trumps accuracy. It really doesn't matter how fast you get the wrong answer.”--Quora.com
Note: "Setting Matters Straight" is a new format: I post on LinkedIn an online Q&A involving data fundamentals that I subsequently debunk in a post here. This is to encourage readers to test their foundation knowledge against our debunking here, where we confirm what is correct and correct what is fallacious. For in-depth treatments check out the POSTS and our PAPERS, LINKS and BOOKS (or organize one of our on-site/online SEMINARS, which can be customized to specific needs). Questions and comments are welcome here and on LinkedIn.
Q: “To what extent is relational database theory related to set theory?”
A: “Relational database theory is indeed closely derived from set theory. Many operations in relational data are directly related to common operations one does with sets. In fact, SQL has keywords for them that should sound familiar to someone who has just taken a class in Discrete Mathematics:Even the structure of a table is set-oriented. A table is a set of rows, and a row is a set of columns, and those columns must match the set of columns defined in the table's header.”
- UNION
- INTERSECT
- DIFFERENCE (called MINUS in Oracle)
--Quora.com
Note: "Setting Matters Straight" (SMS) is a new format: I post on LinkedIn an online Q&A involving data fundamentals that I subsequently debunk in a post here. This is to encourage readers to test their foundation knowledge against our debunking here, where we confirm what is correct and correct what is fallacious. For in-depth treatments check out the POSTS and our PAPERS, LINKS and BOOKS (or organize one of our on-site/online SEMINARS, which can be customized to specific needs).
Q: “How do you return the most recent record in SQL?”
A: “There are many ways of doing it. I would suggest (first thing came to my mind):
Select Top 1
from YourTable
order by TablePrimaryKey Desc;”
A: “If you mean "the last inserted record which has no datetime stamp field" ... you have a few options.
- If you cannot use date/time -- your next best bet would be an auto-increment/sequence field, which assigns increasing numbers to each inserted record.
- If that’s not available, you would have to rely on business logic e.g. order # or some such.
Some vendors, like Oracle, provide ROWID pseudocolumn for each record which might help in some quick’n’dirty cases -- it is not guaranteed to be sequential but could be (e.g., when table has had no DELETE operations).” --Quora.com
If you don't know, I set matters straight @dbdebunk.com.
Note: "Setting Matters Straight" is a new format: I post on LinkedIn an online Q&A involving data fundamentals to encourage readers to test their foundation knowledge, which they can then compare with our debunking here, where we confirm what is correct and correct what is fallacious (with clarifications, wherever necessary). For in-depth treatment check out the POSTS and our PAPERS, LINKS and BOOKS (or organize one of our on-site/online SEMINARS, which can be customized to specific needs).
Q: “What is the difference between a primary key, a unique key, and an index in databases?”
A: “Unique key is a field (or fields) with a set of unique values; the uniqueness is usually enforced with UNIQUE constraint. There might be one or more per table. Every PRIMARY key is always a unique key; there should be only one per table. It uniquely identifies record, and is used to enforce integrity - entity integrity, and, in tandem with FOREIGN key, referential integrity. Index is a data structure to facilitate records search. It might be created on PRIMARY key (best practice), unique key or any other field or combination thereof in the table. The limit on how many indices a table might have is defined in RDBMS implementation. An index might - or might not - speed up some queries.”
A: “The primary key is inherently indexed and unique and is the cross reference to related tables. Often the best primary key is an auto number integer as any value entered by humans is subject to error or delay that can be challenging to manage in the user interface ... whereas an auto number is assigned immediately upfront and eliminates any possible record conflict in tables during multi user entries. A unique key is somewhat of an informal definition. My view is that it is a definition of a field that is not being used as the primary key, but is unique unlike i.e. Last Name -- for instance a social security number field. So it is not the primary key as it is not the field/value being used to cross reference to related tables but it is unique in the table.”
A: “A primary key is a unique, non null value which can identify every tuple (row in the table) uniquely. A unique key/column/constraint ensures that no two rows contain the same value (almost the same as primary key). Unless specified explicitly for the column configuration, a NULL is a valid value for column with unique constraint. A index can be thought of as the appendix at the end of the book. The information is sorted in specific order so that look up is easy and it points to the location that is being searched for.”
--Quora.com
Note: "Setting Matters Straight" is a new format: I post on LinkedIn an online Q&A involving data fundamentals to encourage readers to test their foundation knowledge, which they can then compare with our debunking here, where we confirm what is correct and correct what is fallacious (with clarifications, wherever necessary). For in-depth treatment check out the POSTS and our PAPERS, LINKS and BOOKS (or organize one of our on-site/online SEMINARS, which can be customized to specific needs).
A simple and the answer oversimplifies. But things seem simple only in the absence of foundation knowledge. Practitioners use different terms for the same thing, or the same word for different things, but that must be corrected, not accepted or validated.Q: “What is the relationship between an entity and a record?”
A: “In the context of a database design, an ‘entity’ is a type or category of persons, places, things or events. It’s a collectivisation of the nouns in a system about which you wish to keep data. For example, Employee might be the name of an entity in your system. A ‘record’ is a collection of data about a specific entity, a particular person or place, an identifiable thing, or a single event. For example, Name: ‘Dave Voorhis’, StartYear: 2019, Salary: £1,398,293 might be a record of one Employee entity in your system.”
A: “Database, file, and recordset are basically the same thing. They are collections of information or data. Each database or file or recordset typically has some sort of common purpose or definition. Like a database (relational, hierarchical, etc.) of data of a business process. A File is again a collection of data such as all transactions to be posted. A recordset is also basically a file.
Entity and table are basically the same thing. While you have the grouping of all the data, and entity (logical view) and a table (physical view) are the same. As Dave said, it is a logical grouping of a specific piece of data.
File, recordset, record, row or line are basically the same. A .csv file is a grouping of records. A file is a grouping of records. A row is an individual grouping of data from a relational database.
The last is element or attribute or field. This is the individual piece of data like Transaction_Amount or First Name.”--Quora.com
Note: Each "Test Your Foundation Knowledge" post presents one or more misconceptions about data fundamentals. To test your knowledge, first try to detect them, then proceed to read our debunking, reflecting the current understanding of the RDM, distinct from whatever has passed for it in the industry to date. If there isn't a match, you can review references -- reflecting the current understanding of the RDM, distinct from whatever has passed for it in the industry to date -- which explain and correct the misconceptions. You can acquire further knowledge by checking out our POSTS, BOOKS, PAPERS, LINKS (or, better, organize one of our on-site SEMINARS, which can be customized to specific needs).
“A unique constraint is a type of column restriction within a table, which dictates that all values in that column must be unique [and] allows null values ... a null is the complete absence of a value (not a zero or space). Thus, it is not possible to say that the value in that null field is not unique, as nothing is stored in that field.”This is one of my recent "What's Wrong with this database picture" posts on LinkedIn.
--Techopedia
In the RDM a uniqueness constraint:
Note: To demonstrate the correctness and stability offered by a sound theoretical foundation (relative to the industry's fad-driven "cookbook" practices), I am re-publishing as "Oldies But Goodies" material from the old (2000-06) DBDebunk.com, so that you can judge for yourself how well my arguments hold up and whether the industry has progressed beyond the misconceptions those arguments were intended to dispel. I may revise, break into parts, and/or add comments and/or references, which I enclose in square brackets).
(originally posted 2/21/01)
In Part 1 debunked a review of my book @Slashdot.Org. In parts 2-5 I tackled the discussion generated there by the review. In this last part I focus on the discussion of data hierarchies covered in chapter 7 of my book [the in-vogue re-emergent graph fad].
“Chapter 7 discusses data hierarchies and trees. In a nutshell: there are no trees in SQL. The author is distressed by this. Given that a foreign key is basically a pointer, you can store trees in databases, it might not be pretty and there may not be easy way to read them and it might not be a good thing to do - but if you feel the need then get right in there. Of course I could be totally wrong about this.”Confusing keys with pointers is one of the major errors many practitioners make ]. One intentional core advantage of the RDM is precisely that it prohibits pointers -- both physical and, as in object-orientation, logical. Exposing pointers to users has caused many unnecessary problems and complications, but offered no benefit (Don't Mix Pointers and Relations and Don't Mix Pointers and Relations - Please! in Date's RELATIONAL DATABASE WRITINGS 1994-1997). There is an easy way to demonstrate that relational keys are not, like object IDs (OID), pointers, but values: they represent uniquely identifying names/attributes of rel world entities. Pointers are system-generated internals and have no real world counterpart. The desirability of a data model that produces logical models that are faithful representations of the real world, without adding artifacts of their own. Indeed, as Date points out in Why The Object Model' is Not a Data Model in his above-mentioned book, the fact that "in the object world all the references to objects are by means of their corresponding OIDs explains why -- as is well known -- OO systems typically provide (a) two different equality comparison operators, equal OID vs. equal value and (b) two different assignment operators, assign OID vs. assign value. Note the added complication -- what is the benefit?
Note: To demonstrate the correctness and stability due to a sound theoretical foundation relative to the industry's fad-driven "cookbook" practices, I am re-publishing as "Oldies But Goodies" material from the old DBDebunk.com (2000-06), Judge for yourself how well my arguments hold up and whether the industry has progressed beyond the misconceptions those arguments were intended to dispel. I may revise, break into parts, and/or add comments and/or references. You can acquire foundation knowledge by checking out our POSTS, BOOKS, PAPERS, LINKS (or, even better, organize one of our on-site SEMINARS, which can be customized to specific needs).
(first published @DBAzine.com in 2001)
I was recently contacted by a reporter for an interview. When I expressed my disappointment with the trade media’s tendency to regurgitate vendor marketing claims instead of assessing them, he admitted "that is what happens about 98 percent of the time", but added "There are some outlets with a good piece from time to time that deal with serious architecture issues", mentioning SlashDot as one of them.
There is, of course, a Catch 22 here: to judge the seriousness of such outlets, foundation and substantive knowledge is necessary in the first place. And, alas, reporters possess even less of it than vendors and users (see, for example, The Ignorance Mechanism, On Trade Media’s "Balance"),
without which sources may appear serious even when they are nothing of the sort. As luck would have it, I ran into a good opportunity to prove this point for SlashDot. It so happened that shortly after my exchange with the journalist, Database Debunkings experienced a sudden ten-fold increase in traffic. Now, [given that my target audience is thinking practitioners,] were my material to suddenly become "hot", I would worry as to where I did go wrong. But the odds for that are rather slim and, fortunately, there was no need for concern: an email from a reader informed me that "there recently was an article posted to SlashDot.org which refers to Dbdebunk.com and Mr. Pascal/Date" and "There [were] some 443 comments to that posting." Such volume is practically always indicative of heat (hot air, to be more precise), rather than light. Ah, well, I thought, yet another source of weekly quotes (as if one was needed).
Note: To demonstrate the correctness and stability due to a sound theoretical foundation relative to the industry's fad-driven "cookbook" practices, I am re-publishing as "Oldies But Goodies" material from the old DBDebunk.com (2000-06), Judge for yourself how well my arguments hold up and whether the industry has progressed beyond the misconceptions those arguments were intended to dispel. I may revise, break into parts, and/or add comments and/or references. You can acquire foundation knowledge by checking out our POSTS, BOOKS, PAPERS, LINKS (or, even better, organize one of our on-site SEMINARS, which can be customized to specific needs).
“I did see your plea for help with funding Chris Date. Frankly, I think his approach is "dated", from what I could understand from talking to him at VLDB’99 in Edinburgh. We now live in a world of Agents, Semantic Web and XML. That is our main research focus here. Thus we would not be interested.”--Sr. faculty, Academic Institution
“But within the context of the University of Washington, it would not be my classes where it would be appropriate to present that type of information [on fundamentals]. My classes are graduate level, highly technical and I don’t allow PowerPoint slides or any non-technical content.”--Oracle practitioner, graduate teaching
“Recently, James H. Billington, the current Librarian of Congress, remarked that instead of a knowledge-based democracy, we may end up with an information-inundated democracy. I share his concern, so allow me to end with this simple wish. May, in spite of all distractions generated by technology, all of you succeed in turning information into knowledge, knowledge into understanding, and understanding into wisdom.”--Edsger Dijkstra, Convocation Speech
“A data model is a collection of concepts ... used to describe the structure of a database...data types, relationships and constraints...is basically a conceptualization between attributes and entities ...
The building blocks in the data model are as follows:
- Entity − An entity represents a particular type of object in the real world.
- Entity set − Sets of entities of the same type which share the same properties are called entity Sets.
- Attribute − An attribute is a characteristic of an entity.
- Constraints − A constraint is a restriction placed on the data. It is helpful to ensure data integrity.
- Relationship − A relationship describes an association among entities.
--TutorialsPoint.com
- does not describe (just) the structure of a database.
- is not "a conceptualization between attributes and entities" (whatever that means).
“Let's say I want to store a list of movies that are stored on iTunes. For simplicity, we'll just store a few fields so that the film Avatar has these values:However, sometimes the Synopsis is missing...and sometimes the Year is missing. Without giving it a second thought, I would probably create one table to store those four fields, something like this:ID: 354112018
Name: Avatar
Year: 2009
Synopsis: "From Academy Award®-winning director James Cameron comes Avatar, the story..."Is there any advantage in 'further normalizing' the database so that, for example, I don't store any null values, such as:ID (INT)
Name (VARCHAR)
Year (INT NULL)
Synopsis (VARCHAR NULL)TitleTo me it seems like doing this would potentially create hundreds of extra tables (on a large database) and make inserts a nightmare -- I suppose a View could be created to flatten out the results so it's queryable, but even though I feel like it would require so much overhead. So is there any reason in the above case to normalize to remove nulls, or in general, what would be the case to do so, if there ever is one?” --StackOverflow.com
TitleID
Name
TitleSynopsis
TitleID
Synopsis
TitleYear
TitleID
Year
That we see this in 2022 is testament to abysmal ignorance of fundamentals in the industry. Let's enumerate the fallacies:
Note: To demonstrate the correctness and stability offered by a sound theoretical foundation (relative to the industry's fad-driven "cookbook" practices), I am re-publishing as "Oldies But Goodies" material from the old (2000-06) DBDebunk.com, so that you can judge for yourself how well my arguments hold up and whether the industry has progressed beyond the misconceptions those arguments were intended to dispel. I may revise, break into parts, and/or add comments and/or references, which I enclose in square brackets).
(first published in 2001 @DBazine.com)
The following comments being debunked are by the W3C XML Query Working Group's Activity Lead and by an academic. [The exchange took place when XML DBMS was one of the hottest fads as late as 2013. Consider them in this context: where are XML DBMSs today?]
“The article seems to say ‘I don’t like SQL and I don’t like XML and I think XML Query is about merging them although I don’t understand it very well, so the people working on XML Query must be stupid, and in any case it’s easier to attack people than understand a specification.’ Perhaps that’s unfair, but it’s clear to me that the writer is a little fuzzy on the design goals of XML and also on the focus of SQL development over the past 10 or 15 years. In both cases the story is about interoperability.”
Note: To demonstrate the soundness and stability conferred by a sound theoretical foundation (relative to the industry's fad-driven "cookbook" practices), I am re-publishing as "Oldies But Goodies" material from the old (2000-06) DBDebunk.com, so that you can judge for yourself how well my arguments hold up and whether the industry has progressed beyond the misconceptions those arguments were intended to dispel. In re-publishing I may revise, break into or merge parts and/or add comments and/or references that I enclose in square brackets).
One of the core objectives of this site (and my work) has been to demonstrate that there will not be progress in data management as long as the industry and trade media require and promote exclusively (mainly tool) experience in the absence of foundation knowledge. I have published and analyzed ample evidence that relational language and terminology are used without grasping what it actually means -- a good way to gauge lack of foundation knowledge.
Recently I posted a four part series titled "Nobody Understands the Relational Model" showing that even a practitioner steeped in the RDM does not really understand it. Consider now a practitioner's mistake at the beginning of career -- "a bad database schema and what it did to system performance" -- which, he claims, belatedly taught him a lesson. Hhhhmmm, did it, really?