
Can you identify all the fallacies and misconceptions in the following online exchange? What is the elephant in the room?
Q: “I have done data normalization on dummy data and would like to know if I did it correctly. If it is done correctly, I would also like to ask two things below, because it is about 3NF.
1NF: This table should be 1NF.

2NF: I selected composite key (userID and Doors) as they represent minimal candidate key and got three tables applying FD rule.

3NF: Applying the rule of transitive dependency on 1st table in 2NF, I got out 4 tables (showing only first two, because the last two remain unchanged).
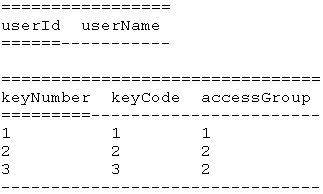
Questions: Is this database normalisation correct? If not could you point me where I did mistake? If answer on first question is True: Should the last table in 3NF be transformed into two tables, given it is not in correct Third normal form. Two non-key atributes have FD keycode -> accessGroup.”